
Introduction
Payroll system integration complexity is what happens when you try to connect a payroll platform to an HRIS, benefits system, time tracking tool, or accounting software — and discover that every provider speaks a different technical language. Different field names, authentication schemes, data hierarchies, and API behaviors mean there's no universal playbook. Every connection requires its own logic.
For HR Tech and benefits platforms, that logic compounds fast. Connect to 5 payroll providers and you're maintaining 5 separate data pipelines. Connect to 20, and the engineering overhead becomes a product liability.
The consequences aren't just technical. According to Ernst & Young research cited by SHRM, a single payroll error costs $291 on average — and 33% of U.S. employers made payroll errors in 2023, contributing to roughly $7 billion in IRS penalties. Poor integration is a primary driver.
What follows is a practical breakdown of the root causes, the real cost of getting it wrong, and the architectural decisions that make the problem go away.
TL;DR
- Payroll integration complexity compounds from fragmented data models, unstable APIs, manual processes, and inconsistent compliance rules across providers and jurisdictions.
- Unresolved complexity produces payroll errors, compliance penalties, slow customer onboarding, and engineering teams stuck in maintenance mode.
- Watch for rising maintenance ticket volume, stretched onboarding timelines, and recurring data discrepancies between systems.
- The most effective fix is a unified API layer that normalizes provider differences — not building native integrations one by one.
- Long-term health requires regular integration audits and treating integration architecture as a product concern — not an afterthought.
What Causes Payroll System Integration Complexity?
Payroll integration complexity is almost never one thing. It's several technical and operational problems hitting at once — and each one gets harder to manage as you add more providers.
Fragmented Data Models Across Providers
No two major payroll providers structure data the same way. ADP uses an opaque associateOID as its employee identifier with nested payData wrappers. Gusto uses a numeric id with snake_case field naming (pay_schedule, start_date). Rippling uses UUID-style strings with camelCase (grossPay). Paychex requires companyId as a path parameter with its own field conventions.
Authentication diverges just as widely:
| Provider | Auth Method | Notable Quirk |
|---|---|---|
| ADP Workforce Now | mTLS + OAuth 2.0 | Requires 2048-bit RSA CSR + legal review |
| Gusto | OAuth 2.0 | Tokens expire every 2 hours |
| Rippling | OAuth 2.0 + Bearer token | Expires after 30 days of inactivity |
| Paychex Flex | OAuth 2.0 client_credentials | Only provider returning Retry-After on rate limit |

A platform connecting to 10 payroll systems must maintain 10 separate data transformation pipelines. Each new provider added multiplies both build time and ongoing maintenance — there's no shared logic to reuse.
API Instability and Legacy File-Based Systems
Many payroll APIs are underdocumented, subject to breaking changes without notice, or rate-limited with no published thresholds. ADP layered its Marketplace API (launched 2017) over decades of legacy infrastructure, adding 2–4 weeks of legal review and mTLS certificate setup on top of standard development time. Legacy platforms like older Ceridian/Dayforce implementations still require SFTP/CSV file exports for many integration scenarios.
That instability has a direct operational cost. When a provider pushes an undocumented change to production, live customer connections break — triggering support escalations, manual data fixes, and unplanned engineering sprints that weren't on anyone's roadmap.
Manual Data Handling and Lack of Automation
When integrations lack automated syncing, HR teams fill the gap manually. New hire records entered in the HRIS don't propagate to payroll. Termination data sits in one system while the other keeps processing pay. Source data that's never synchronized causes benefits deductions to miscalculate.
Paycom reports that approximately 1 in 5 payrolls contains errors — manual data handling between disconnected systems is a primary contributor. Each instance creates downstream work: reconciliation, corrections, employee complaints, and potential compliance exposure.
Compliance and Security Requirements
Payroll data is subject to GDPR, HIPAA, SOC 2, IRS Publication 1075, and local data residency laws. Every integration point is a potential exposure. IBM/Ponemon's 2024 research shows employee PII is involved in 40% of breached records, at $189 per compromised record, with average breach costs reaching $4.88 million.
Compliance doesn't exist alongside integration complexity — it multiplies it. A platform expanding internationally must handle new provider APIs and new data handling obligations per jurisdiction at the same time, typically without any shared tooling to address either.
The Real Cost of Ignoring Integration Complexity
Unresolved payroll integration complexity creates compounding business damage across three areas:
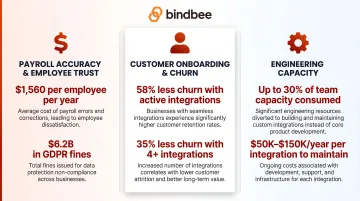
Payroll accuracy and employee trust
- Incorrect pay or missed deductions erode trust quickly
- Combined payroll, HR, and compliance errors cost an estimated $1,560 per employee per year
- Compliance penalties compound over time — GDPR fines have totaled approximately €5.88 billion (roughly $6.2 billion USD) cumulative through January 2025
Customer onboarding and churn
- Slow integrations delay time-to-value for new customers
- Users with active integrations are 58% less likely to churn — integration depth is a direct retention lever
- Customers with 4+ integrations are 35% less likely to churn, making coverage a measurable revenue factor
- For deals above $75,000 ACV, integration coverage is evaluated early in the sales cycle and treated as non-negotiable
Engineering capacity
- Integration maintenance can consume up to 30% of a B2B SaaS engineering team's total capacity
- An advanced payroll integration (covering deductions, benefits enrollment, bidirectional sync) costs $30,000+ to build and $50,000–$150,000 per year to maintain
- Engineering teams stuck maintaining integration debt aren't building the product features that drive growth
These costs don't stay contained. When integration debt compounds long enough, it starts showing up in your sprint board, your sales calls, and your support queue.
Warning Signs You're Approaching a Breaking Point
Watch for these signals before the problem becomes critical:
- Sprint capacity imbalance — A disproportionate share of engineering cycles goes to integration maintenance tickets rather than new features
- Delayed onboarding timelines — Each new payroll provider connection requires custom development, pushing time-to-value from days to weeks
- Recurring data discrepancies — Persistent mismatches between payroll and connected platforms (HRIS, benefits, accounting) that require manual reconciliation and trigger employee complaints
How to Reduce Payroll System Integration Complexity
The goal isn't to manage integration complexity indefinitely — it's to eliminate the root causes through deliberate architectural choices.
Adopt a Unified API Layer Over Native Integrations
A unified API layer abstracts the differences between payroll and HRIS providers behind a single normalized interface. Instead of building 20 separate integrations, a platform builds one — and the unified layer handles provider-specific field mappings, authentication quirks, pagination differences, and API version changes.
This directly addresses the two biggest complexity drivers: fragmented data models and API instability. The unified layer absorbs both, so product teams consume clean, consistent data regardless of what's happening upstream.
The economics follow. Building a single native integration takes 3–6 weeks minimum (add 2–4 weeks for ADP specifically). Bindbee's unified API — connecting 60+ HRIS, payroll, and benefits systems — cuts setup to under one day, with most customers completing authentication in under 10 minutes via Magic Link. Provider-side changes and API version updates are handled internally, so they never reach customer engineering teams.
Real deployments back this up: Newfront cut integration deployment time from 8–12 weeks to 48 hours and achieved a 90% reduction in engineering time on integration work. Budgie Health connected 30 HR and payroll integrations in 4 days, saving 5 man-months of engineering bandwidth.
Standardize Data Models Before Building Integrations
Define a canonical data model — a standardized schema for employee, payroll, compensation, and benefits data — before writing a single integration. All incoming data maps to this standard on ingestion.
When a new payroll provider is added, only the mapping layer changes. The platform's core logic stays untouched. Bindbee's unified schema covers distinct models for:
- Employee and Compensation
- Payroll Runs and Employee Payroll Runs
- Benefits, Dependents, and Bank Info
Each is normalized consistently regardless of source system.
Add validation rules at the integration boundary to catch mismatches early. Detecting a field format mismatch at ingestion is far cheaper than finding a payroll calculation error two weeks later.
Automate Sync Processes and Build Robust Error Handling
Scheduled incremental syncs keep payroll and HR data current without engineering intervention. Webhook-based triggers for key lifecycle events — new hires, terminations, benefit elections, compensation changes — reduce lag between systems from hours or days to near real-time.
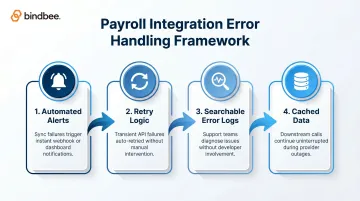
A basic error handling framework should include:
- Automated alerts when syncs fail, delivered via webhook or notification dashboard
- Retry logic so transient API failures don't require manual re-runs
- Searchable error logs that support teams can use to diagnose issues without developer involvement
- Cached data so downstream API calls continue working during provider outages
Grazzy eliminated the biweekly manual CSV export workflow — previously required for roughly 75% of customers — by switching to automated payroll writeback through Bindbee's unified API. Clever Benefits eliminated manual deduction entry entirely and now spends zero time on reconciliation each pay cycle.
Build Compliance and Security Into the Integration Architecture
Configuring role-based access controls, end-to-end encryption for data in transit and at rest, and audit trails at the integration layer from day one costs far less than retrofitting them after the fact. SOC 2 Type II, HIPAA, and GDPR compliance should be baseline requirements built into the architecture.
The operational payoff: when compliance is embedded in the architecture, adding a new jurisdiction or serving a customer with different regulatory requirements doesn't require rebuilding the integration. Multi-region data residency (US, EU, APAC) handles data sovereignty requirements without separate infrastructure per region.
Tips for Long-Term Payroll Integration Health
Getting the architecture right is only half the work. These practices keep integrations reliable as your platform scales:
- Run quarterly audits tracking sync success rates, error frequency, and latency across all connected payroll providers. Treat this as a standing operational metric — and flag "zombie integrations" (unused connections) that drain resources without value.
- Monitor provider changelogs actively, maintain a staging environment to test updates before production, and assign explicit ownership for integration maintenance within engineering or product.
- Document every integration's data flow, field mappings, and provider quirks — and keep it current. Institutional knowledge locked in one engineer's head is a liability a maintained knowledge base eliminates.
- Replace scheduled full-data polls with event-based webhooks for lifecycle events: new hires, terminations, and dependent changes. Bindbee's webhooks fire the moment a change occurs in the employer's HRIS, rather than hours later through a batch process.
Conclusion
Payroll system integration complexity has identifiable causes — fragmented data models, unstable APIs, manual processes, and compliance gaps — and each one can be addressed with the right architectural decisions. Most platforms approach it reactively, building native connections one at a time until maintenance debt crowds out everything else.
Treating integration as infrastructure — not a feature backlog item — is what separates teams that stay ahead of fragmentation from those that keep catching up to it. Platforms that standardize data models, automate sync, and route through a unified API layer protect engineering bandwidth and accelerate customer onboarding. Compliance requirements stop requiring ground-up rebuilds every time a regulation or system changes. That's the practical case Bindbee is built on: one normalized API across 60+ payroll and HRIS systems, so teams ship integrations in days rather than quarters and maintain them without ongoing engineering overhead.
Frequently Asked Questions
What are common challenges in the payroll processing cycle?
Common challenges include data entry errors from manual processes, inconsistent data across disconnected HRIS and payroll systems, compliance failures from outdated tax rules, and delayed processing caused by poor system integration. When these systems don't communicate, each failure amplifies the next — a missed field update can cascade into a compliance gap by the next pay run.
What is 180 or 360 payroll integration?
180-degree integration is a one-way data flow — for example, an HRIS pushing employee records into a payroll system. 360-degree integration is bidirectional: data flows both ways, so both systems stay in sync without manual updates when changes occur in either direction.
Why is building native payroll integrations so expensive?
Each payroll provider has unique APIs, data structures, and authentication requirements, so every native integration requires separate development, testing, and ongoing maintenance. Costs multiply quickly — an advanced integration can run $30,000+ to build and $50,000–$150,000 per year to maintain, per provider.
What is the difference between file-based and API-based payroll integration?
File-based integrations (SFTP/CSV) use scheduled batch transfers and are common with legacy enterprise systems. API-based integrations enable real-time data exchange and are more accurate and scalable — but depend on each provider exposing a stable, well-documented API.
How do you maintain payroll integrations as providers update their APIs?
At minimum: monitor provider changelogs, test updates in a sandbox before deploying to production, and assign clear ownership per connection. A unified API layer is the most scalable approach — it absorbs provider-level changes so upstream updates never reach your core platform.
How long does it take to build a single payroll system integration?
A native integration typically takes 4–8 weeks — longer for providers like ADP that require additional legal and certificate setup. Bindbee reduces this to under one day with pre-built, normalized connectors across 60+ systems.


