
Introduction
Most HR Tech and Benefits platforms are managing employee data flowing in from dozens of HRIS, payroll, and benefits systems simultaneously — and most of it still moves manually. The downstream consequences are predictable: delayed employer onboarding, stale eligibility records, enrollment errors, and engineering teams debugging integration failures instead of shipping product.
The HR technology market now spans over 3,800 vendors globally, with large enterprises typically running at least nine separate HR systems. Every new employer connection is another integration surface. Every manual file export is another opportunity for data to go stale.
In HR Tech, data automation has a specific job. It determines how quickly a new employer goes live, how accurately benefits eligibility updates after a life event, and whether a platform can scale to hundreds of employer connections without proportional engineering cost.
The platforms pulling ahead aren't necessarily building better features — they're moving employer data faster, keeping eligibility cleaner, and spending less engineering time on integration upkeep. This article breaks down exactly how data automation drives those outcomes.
TL;DR
- Data automation replaces manual exports, spreadsheets, and custom scripts with persistent pipelines that keep employment data current automatically.
- HR Tech platforms gain faster employer onboarding, cleaner eligibility data, and integrations that scale without adding engineering headcount.
- Without automation: slower onboarding cycles, reactive data fixes, and integration maintenance eating into core product bandwidth.
- New employer connections go live in hours, not weeks — and data stays current instead of aging between batch exports.
What Is Data Automation?
Data automation is the use of software to automatically extract, normalize, and deliver data from source systems to destination systems — on a schedule, via triggers, or in near real time — without manual steps between systems.
In the HR Tech context, this means automatically syncing employment data across HRIS platforms, benefits carriers, payroll systems, and third-party applications — no file uploads, no custom per-employer scripts. The data types this covers include:
- Employee records and eligibility status
- Benefits elections and dependent information
- Payroll data and deduction mappings
- Life event triggers and carrier reconciliation inputs
Data automation is infrastructure, not a feature. It's the underlying capability that keeps every downstream workflow — benefits enrollment, eligibility verification, COBRA detection, carrier reconciliation — accurate and timely.
Without this layer, every workflow that depends on employment data inherits the delays and errors of the manual processes feeding it.
Key Advantages of Data Automation
The advantages below aren't theoretical. Each maps to a metric that HR Tech and Benefits platforms actually track: time-to-live for new employers, error rates in benefits data, engineering hours on integration maintenance, and the ability to expand HRIS coverage without rebuilding from scratch.
Advantage 1: Faster Employer Onboarding and Time-to-Value
Automated data integrations allow HR Tech platforms to connect a new employer's HRIS or payroll system and begin receiving live, normalized data in hours — rather than waiting weeks for a custom integration to be scoped, built, and tested.
Instead of writing bespoke ETL scripts per employer, automated integration infrastructure normalizes data from dozens of sources through a single pre-built pipeline. Each new employer follows the same path, not a new one.
Why this matters:
Time-to-value is a direct sales and retention metric. Forrester identifies customer onboarding as the launchpad to customer value — the first impression that determines whether customers see the platform's value before they have a reason to question it. Employers who go live faster, see results sooner, and churn less.
Legacy HR integrations historically required 3–6 months. Modern automated approaches have compressed single-system connections to hours — and the gap between those two timelines is a direct competitive advantage in every enterprise sales cycle where go-live speed is a comparison point.
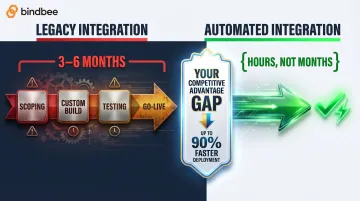
Platforms using pre-built automated integration infrastructure see this concretely. Phin, an HR Tech platform running on Bindbee's unified API, reduced employer onboarding time by 76% and achieved a 94% optimization in Time-to-Value — cutting what had been a 2+ month integration cycle per HRIS down to 48 hours, while recovering $115,000+ in annual development costs.
KPIs impacted:
- Time-to-live for new employer connections
- Customer activation rate
- Onboarding-related churn
- Engineering hours per new employer integration
When it matters most: Scaling employer volume rapidly, entering new verticals with different HRIS ecosystems, or competing against platforms that use go-live speed as a sales differentiator.
Advantage 2: Higher Data Accuracy and Reduced Eligibility Errors
Automated data pipelines enforce consistent validation rules and deliver near-real-time updates — so benefits eligibility records, dependent relationships, enrollment elections, and coverage effective dates stay current without manual reconciliation.
Instead of relying on periodic file exports from an HRIS (which may be delayed, incomplete, or formatted inconsistently), automated systems pull incremental updates continuously, flag anomalies, and normalize data to a consistent schema before it reaches downstream systems.
Why this matters:
The scale of the problem is well-documented. A Nava Benefits audit of over 600 insurance carrier bills found that 90% contained enrollment errors — with aggregate costs reaching into the billions annually. EY research found approximately 20% of payrolls contain inaccuracies, with each error costing an average of $291 to correct.
The compliance exposure compounds that financial risk:
- ACA information reporting errors can exceed $300 per erroneous report, scaling across every employee record filed incorrectly
- HIPAA civil monetary penalties range from $145 to $2,190,294 per violation depending on severity — and large healthcare data breaches doubled from 369 in 2018 to 747 in 2023
- "Ghost employee" scenarios — terminated employees remaining on benefit rolls due to stale data — create recurring financial leakage that compounds with employer scale

For platforms serving enterprise employers with ACA or HIPAA compliance requirements, data accuracy is a procurement filter. Buyers in regulated industries ask directly about data freshness and validation controls — and platforms without a clear answer get eliminated before the shortlist.
KPIs impacted:
- Benefits enrollment error rate
- Eligibility discrepancy rate
- Support tickets related to data issues
- Compliance audit pass rate
When it matters most: Open enrollment periods, post-M&A record merges, life events (new hires, terminations, dependent changes), and any industry with strict ACA or HIPAA requirements.
Advantage 3: Scalability Without Proportional Engineering Cost
Every new employer connection built on a custom integration is technical debt that compounds. As employer volume grows, so does the maintenance burden — until the integration team becomes the bottleneck to sales and customer success velocity.
A normalized automated data layer abstracts away the complexity of individual HRIS and payroll systems — meaning one set of integration logic scales across 60+ systems rather than needing 60 separate codebases to maintain.
Why this matters:
A survey of 500 US-based IT and engineering leaders found that 40% of team time is spent building and maintaining internal tools and workflows — with 76% calling it a distraction from revenue-driving product work. Stripe's Developer Coefficient research puts the maintenance burden even more starkly: developers lose 17.3 hours per week to debugging and refactoring out of a 41-hour average work week.
When integration maintenance is handled by the infrastructure layer — including API changes, deprecations, and schema updates from upstream systems — engineering teams recover that bandwidth for roadmap work. Platforms that offload this to infrastructure ship product features; those that don't spend their next sprint on someone else's API deprecation.
Bindbee customers document this directly. Newfront reduced engineering time on integration development by 90%, cutting deployment time from 8–12 weeks to 48 hours. A Newfront staff engineer put it plainly: "What used to take 6 engineers 6 months now takes 1 engineer 1 week." Budgie Health saved 5 man-months of technology team bandwidth. Healthee redirected $150,000+ in annual development costs toward their core AI product instead of integration maintenance.
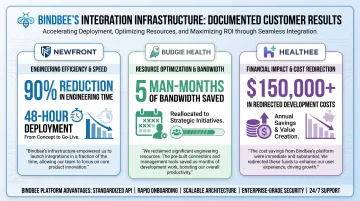
KPIs impacted:
- Engineering hours: integration maintenance vs. product development
- Cost per employer connection
- Number of supported HRIS systems
- Time to add a new integration
When it matters most: Platforms with more than 10–15 employer connections, employers using a wide variety of HRIS systems, or situations where the integration team is a bottleneck to sales and customer success velocity.
What Happens When Data Automation Is Missing
The consequences aren't hypothetical — they're operational and financial, and they compound:
- Each new HRIS connection requires custom engineering work, slowing time-to-revenue and frustrating customers before they've seen any platform value.
- Between manual export cycles, enrollment errors accumulate — generating claims disputes, compliance exposure, and damaged employer relationships, especially during open enrollment or post-acquisition transitions.
- Teams spend a disproportionate share of capacity maintaining and debugging existing integrations instead of building product features that actually differentiate.
- As employer volume grows, more systems to maintain means more one-off fixes and more brittle connections — until scaling becomes structurally impossible without significant re-architecture.
Consider 50 employer connections across 15 different HRIS systems, each with periodic API updates. That maintenance surface grows with every new employer added — and manual integration complexity doesn't scale linearly. It compounds.
How to Get the Most Value from Data Automation
Data automation delivers the most value when applied as foundational infrastructure — not as a patchwork of point-to-point connections.
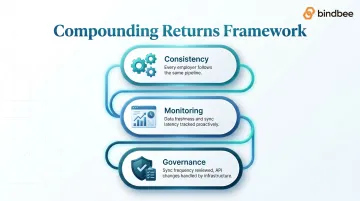
Three principles for compounding returns:
- Consistency — every employer connection follows the same pipeline, not a custom one
- Monitoring — data freshness, error rates, and sync latency are tracked as operational metrics, not discovered reactively through support tickets
- Governance — sync frequency is reviewed against business needs, data completeness is audited for dependent and benefits fields, and API changes are handled by the infrastructure layer, not by internal engineers
The fastest path to value is adopting pre-built integration infrastructure rather than building from scratch. Unified API platforms that already normalize data from dozens of HRIS and payroll systems eliminate upfront engineering cost and ongoing maintenance burden. Setup time drops from 4–8 weeks for native integrations to under a day.
With Bindbee, most employer connections complete in under 10 minutes via Magic Link authentication, with initial data sync completing immediately.
Bindbee's infrastructure includes:
- 60+ HRIS, payroll, and benefits system connectors through a single normalized API
- Built-in sync with webhooks for life events (new hires, terminations, dependent changes, qualifying events)
- Zero maintenance overhead for API updates or upstream schema changes
- SOC 2 Type II, ISO 27001, HIPAA compliance, and GDPR readiness — critical when benefits data includes protected health information
Over 50 benefits platforms — including Newfront, Healthee, Pasito, Alma, and Clever Benefits — run on this infrastructure.
Data automation isn't a one-time implementation. Ongoing governance — reviewing sync frequency, auditing data completeness, ensuring the infrastructure layer handles new system versions — is what separates platforms that compound advantage over time from those that automate once and let the infrastructure drift.
Conclusion
For HR Tech and Benefits platforms, data automation is the operational foundation that determines how fast they can onboard employers, how reliable their benefits data is, and how efficiently they can scale without accumulating integration debt.
Platforms that automate data infrastructure early redirect engineering capacity toward product differentiation. Those that rely on manual processes spend increasing resources just keeping existing connections alive — and the gap between the two widens with every new employer added.
The question isn't whether to automate — it's how much ground you're willing to cede while you wait. Platforms that build on a unified integration layer like Bindbee's skip the rebuild cycle entirely and start compounding from day one.
Frequently Asked Questions
What are the benefits of data automation?
Data automation eliminates manual entry errors, accelerates decision-making through continuous syncs, and cuts operational costs by replacing hand-operated workflows. It also lets platforms scale data operations without proportional increases in headcount or engineering resources.
What are the 5 D's of automation?
The 5 D's framework identifies tasks best suited for automation: Dull (repetitive, low-value work), Dirty (messy or error-prone processes), Dangerous (compliance-risk tasks), Demeaning (work that sits well below your team's actual capability), and Dear (tasks that cost too much when done manually). In HR Tech, manual benefits data reconciliation checks every box.
How does data automation create a competitive advantage?
Automation enables faster employer onboarding (hours instead of weeks), more reliable data quality with fewer downstream errors, and the ability to scale connections without rebuilding integrations. Competitors relying on manual processes accumulate technical and operational debt that compounds as they grow.
What is the difference between manual and automated data integration?
Manual integration requires human steps (file exports, uploads, custom scripts per system) introducing delays and errors at each handoff. Automated integration uses persistent pipelines that sync data continuously or on-trigger, normalize it to a standard schema, and surface exceptions without human intervention.
How long does it take to see ROI from data automation in HR Tech?
Building native integrations internally can take months before delivering value. Leveraging pre-built unified API infrastructure can deliver ROI within weeks by eliminating integration backlog and accelerating employer onboarding immediately — with engineering time recovered from maintenance from day one.
What are the biggest risks of ignoring data automation in benefits administration?
Three risks compound over time as employer volume grows:
- Stale eligibility data triggers enrollment errors and claims disputes
- Inaccurate coverage records create ACA and HIPAA exposure, with penalties scaling per employee
- Engineering bottlenecks prevent the platform from adding employer connections at pace


