
Getting this data wrong is expensive. Incomplete or inaccurate census submissions lead to mispriced quotes, delayed renewals, and post-enrollment rate corrections that catch employers off guard. This guide covers what census data is, which fields matter, how it flows through the bidding process, and where things typically break down.
TL;DR
- A benefits census is a point-in-time workforce snapshot — demographics, employment details, and dependent data — submitted to carriers to generate group quotes
- Census data quality directly determines quote accuracy; missing or stale records often trigger rate corrections after enrollment
- Required fields cover personal demographics, dependent details, employment classification, compensation, and current coverage elections
- The bidding sequence runs: internal compilation → broker validation → carrier underwriting → quote generation → plan selection
- Pulling census data directly from HRIS and payroll systems via API eliminates manual errors and compresses the bidding timeline from weeks to days
What Is Employee Census Data in the Context of Benefits Bidding?
In the benefits bidding context, an employee census is the structured, employer-submitted dataset that insurers and brokers use to assess group risk, model utilization, and calculate premiums. It applies across all major benefit lines — group health, dental, vision, life, and disability. As Word & Brown puts it: "The census summarizes your group information, so the carrier can provide a better quote."
This is distinct from other HR uses of workforce data. Census files serve different masters depending on context:
- 401(k) census — supports nondiscrimination and compliance testing
- Payroll census — feeds tax reporting and wage reconciliation
- Benefits bidding census — carrier-facing, underwriting-focused, and directly tied to cost outcomes
What you submit determines what you pay.
When Is Census Data Required?
Census submission is triggered at several points in the benefits lifecycle:
| Trigger Event | Purpose |
|---|---|
| Initial group setup | First-time carrier quoting for new groups |
| Annual renewal / open enrollment | Re-rating coverage based on updated workforce demographics |
| Carrier switch / market check | Soliciting competitive bids from alternative carriers |
| Adding benefit lines | Quoting new coverage types (e.g., adding vision or disability) |
Life and disability carriers also use salary data from the census to calculate benefit amounts — so compensation fields matter beyond just health plan quoting.
What Goes Into a Benefits Census: Required Data Fields
Carriers require data at two levels: the employee level and the dependent level. Missing data at either level forces carriers to make assumptions, and those assumptions almost always inflate premiums.
Personal and Demographic Data
The core personal fields every carrier requires:
- Full legal name and date of birth (age is a primary ACA rating factor; under 45 CFR 147.102, premiums for adults can vary at a maximum 3:1 ratio based on age)
- Home ZIP code / state: geographic rating area is one of only four permitted rating factors for fully insured small group plans
- Tobacco use status: carriers can apply up to a 1.5:1 surcharge for tobacco users under ACA rules
- Gender, marital status, SSN (typically last 4 digits): required for identity verification and dependent relationship validation
Employment and Eligibility Data
Employment fields determine who belongs in the quote pool:
- Hire date, rehire date, and termination date (for departing employees)
- Employment classification: full-time vs. part-time
- Hours worked per week: 30+ hours per week equals full-time under the ACA, making this field critical for large employer determinations
- Job title, employee ID, union status, and salary: used for life and disability benefit calculations
Dependent Data
Dependent data is the most commonly incomplete portion of any census, and it carries an outsized impact on group quotes. Required fields per dependent:
- Full name, date of birth, and SSN
- Relationship type: spouse, child, or domestic partner
Children aging out at 26 and post-divorce dependents are frequently not updated in HRIS systems. These ghost dependents skew carrier risk calculations and inflate premiums for coverage periods when the dependent was no longer eligible.
Current Coverage and Enrollment Elections
Carriers often want to see existing enrollment alongside demographic data:
- Which employees are enrolled and on which tier (employee only, employee + spouse, family)
- Waiver status for employees who declined coverage
- Effective dates of current coverage
This data typically lives in a benefits administration platform separate from the core HRIS, which creates its own problems covered in the next section.
How Census Data Drives the Benefits Bidding Process
The end-to-end flow: HR compiles census → broker validates and formats it → broker submits to multiple carriers simultaneously → carriers run underwriting models → quotes return with plan options and rates → employer selects plan(s) → enrollment begins.
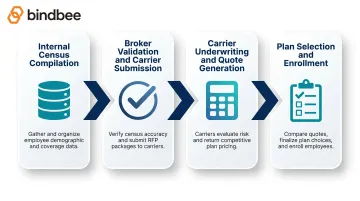
At each step, census accuracy determines whether the process moves cleanly or stalls.
Step 1: Internal Census Compilation
Employers must pull from at least three separate sources:
- Core HRIS — personal demographics, employment classification, hire dates
- Payroll system — compensation tiers, hours worked, deduction history
- Benefits administration platform — current enrollment elections, dependent information, coverage tiers
Fragmentation across these systems is the most common source of delays and errors. A termination processed in payroll may not propagate to the benefits platform for weeks, leaving the departed employee in the census pool.
Bindbee's Census Data Sync addresses this by pulling normalized data from 60+ HRIS, payroll, and benefits systems through a single API — no spreadsheet exports. The sync surfaces employee demographics, dependent data (relationship type, DOB, SSN), coverage tiers, and effective dates in real time. Newfront cut their integration time from 12 weeks to 48 hours after adopting this approach.
Step 2: Broker Validation and Standardization
Brokers receive the raw census and perform validation before carrier submission. That validation work typically includes:
- Checking for missing required fields (DOB, ZIP, coverage tier)
- Correcting formatting inconsistencies across source systems
- Flagging employees who don't meet eligibility thresholds
- Reformatting data to match each carrier's template (Excel, SFTP upload, or portal)
Formatting errors are a leading cause of quote rejections and delays — and carriers rarely explain why a submission failed.
Step 3: Carrier Underwriting and Quote Generation
Carriers use census data to run underwriting models. The key inputs: age distribution (age banding), ZIP code rating areas, family tier composition, group size, and tobacco prevalence.
The rating methodology depends on group size:
| Rating Type | Group Size | Primary Census Inputs |
|---|---|---|
| Community-rated (ACA) | 1–50 employees (up to 100 in some states) | Age, ZIP, tobacco, family size |
| Experience-rated | 51+ (or 101+ depending on state) | All census fields plus claims history |
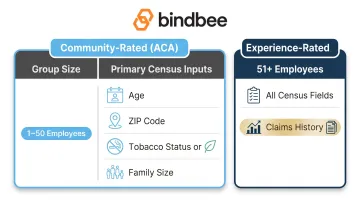
For small groups, individual health factors are not used — only the four ACA-permitted factors. For large groups, carriers factor in the group's actual claims history, making accurate baseline demographics essential — carriers will reconcile claims against the census at renewal.
Step 4: Comparing Quotes and Selecting Plans
The resulting quotes are compared across carriers on four dimensions:
- Plan design and coverage structure
- Network breadth and provider access
- Employee premium contribution levels
- Total employer cost
An accurate census is what makes this comparison valid. If different carriers received different census versions, rate comparisons become unreliable — the "best" quote may be built on workforce assumptions that no longer apply.
Key Factors That Affect Census Data Quality and Bidding Outcomes
Census accuracy is not static. Every new hire, termination, life event, and dependent change erodes the accuracy of what was submitted at your last renewal. Bidding outcomes are only as reliable as the data at the time of RFP.
Data Recency and the Cost of Stale Records
Empyrean estimates that benefits billing errors cost 1% to 2% of total premium spend annually. For an employer with 1,000+ covered workers, that's a potential exposure of $270,000 to $540,000 — driven by stale eligibility records, missed terminations, and dependents who should have been removed months earlier.

Carriers quote based on a point-in-time snapshot. Outdated enrollment data can result in:
- Rate corrections post-enrollment
- Retroactive billing adjustments
- Carrier audit findings
- Compliance exposure under ACA reporting obligations
System Fragmentation as a Data Quality Problem
When employee personal data lives in one HRIS, compensation in a payroll system, and enrollment in a separate benefits administration platform, inconsistencies accumulate. A change made in one system rarely propagates automatically to the others.
Bindbee addresses this by acting as the integration layer, pulling normalized data from all three source systems through a single API with automatic incremental syncs and real-time webhooks. When employment status, hours, or dependent enrollment changes, the event fires immediately — not at the next monthly CSV export.
The platform also applies built-in eligibility intelligence at the sync level: ACA hours validation, waiting period calculations, benefit class assignment, and dependent age-out detection. These checks run before census data ever reaches the broker or carrier.
The 50-Employee Threshold
At 50 full-time equivalent employees, two things change simultaneously.
Carrier rating methodology shifts. Groups under 50 are community-rated under ACA rules, where individual census data has limited impact on any single group's premium. Groups over 50 (or 100 in some states) may be experience-rated, where your specific demographic profile and claims history drive rates directly.
ACA compliance obligations activate. Applicable Large Employers (ALEs) must file Forms 1094-C and 1095-C under IRC Section 6056, reporting coverage offers to all full-time employees. The workforce data required — employee identifying information, full-time status, months of coverage offered — overlaps substantially with census fields. At this threshold, accurate census maintenance becomes a compliance requirement, not just a quoting convenience.
Common Issues and Misconceptions About Benefits Census Data
"We only need the census once a year at renewal"
Life events and employment changes don't wait for renewal season. New dependents, marriages, divorces, births, and terminations require continuous updates to maintain eligibility accuracy. Stale census data submitted at renewal is one of the most common causes of carrier audit findings — the carrier's underwriting assumptions don't match who's actually covered.
"Our census file is the same as our enrollment file"
These are different things. A census is the input used to generate quotes and model costs. An EDI 834 enrollment file is the output that tells a carrier who is actually covered and at what tier. Submitting an enrollment file as a census (or vice versa) results in misquotes or eligibility errors downstream.
| Benefits Census | EDI 834 Enrollment File | |
|---|---|---|
| Purpose | Generate carrier quotes | Add, change, or terminate enrollment |
| Timing | Point-in-time snapshot | Ongoing transactional exchange |
| Format | Excel or CSV | ASC X12 standard transaction set |
| Direction | Employer/broker → carrier (pre-sale) | Employer/TPA → carrier (post-sale) |
Getting those two files straight matters. But confusing census and enrollment files isn't the only misconception that costs employers money.
"Dependent data matters less than employee headcount"
This is the most expensive misconception. Research by Geruso and Rosen found that 3% to 15% of enrolled dependents may be ineligible in a typical health plan. When Goodyear audited its dependent roster in 2005, it removed 13% of 70,000 dependents — reducing total healthcare costs by 6%.

The financial stakes of dependent data errors go both ways:
- Over-reporting ineligible dependents inflates premiums by increasing the covered population used in carrier rating
- Under-reporting eligible dependents creates compliance exposure: ALEs may face Employer Shared Responsibility Payments if excluded individuals obtain Marketplace coverage with premium tax credits
Frequently Asked Questions
What should be included in an employee census?
A benefits census should include personal demographics (name, date of birth, home ZIP code, tobacco status), employment details (hire date, classification, hours worked, salary), dependent information (name, DOB, relationship type), and current enrollment elections. Exact required fields vary by carrier and plan type.
What is an employee benefits census?
An employee benefits census is a structured workforce data report submitted specifically to insurance carriers and brokers to obtain group benefits quotes, assess risk, and determine premium rates. Unlike payroll reports or compliance filings, its sole purpose is underwriting and quoting.
What is an employee census file?
An employee census file is the formatted document — typically a spreadsheet or structured data export — containing all required employee and dependent data fields submitted to brokers or carriers during the benefits bidding or renewal process.
Is completing an employee census mandatory?
No federal law mandates a standalone employee census, but carriers require it as a condition of generating group quotes. ACA reporting obligations (Forms 1094/1095) for ALEs require substantially similar workforce data, so employers with 50+ employees effectively need accurate census data to meet both carrier and ACA requirements.
Are firms with more than 50 employees required to offer their employees insurance?
Under the ACA, employers with 50 or more full-time equivalent employees (Applicable Large Employers) must offer minimum essential coverage to full-time employees or face potential Employer Shared Responsibility Payments. That threshold is calculated from hours-worked data in your census, so accurate FTE counting determines whether this obligation applies to your organization.


